
Anonymization Challenges
In a properly managed DevOps environment, only anonymized data should be available in Dev/Test databases.
 The Dev/Test database environment should be open by nature with little constraints in order not to impair the work of the Designers, Developers and Testers
The Dev/Test database environment should be open by nature with little constraints in order not to impair the work of the Designers, Developers and Testers- The data on those environments should be as close as possible to Prod data but should be protected. The best way to handle this “dilemma” is to anonymize sensitive data for two main purposes:
– Complying with legal and regulatory concerns about sensitive personal data protection
– Protecting business data from possible breaches


Anonymization technical constraints
When data is anonymized, it is imperative not to break existing application constraints and validations
- Preserving the inner coherence of composite data (e.g.: address with street, city, zip…)
- Preserving the structure rules of the data (e.g.: Credit Card, Iban… structure)
- Preserving dependency rules (e.g.: Social Security number might contain birth date which is also stored in a different column of the record)
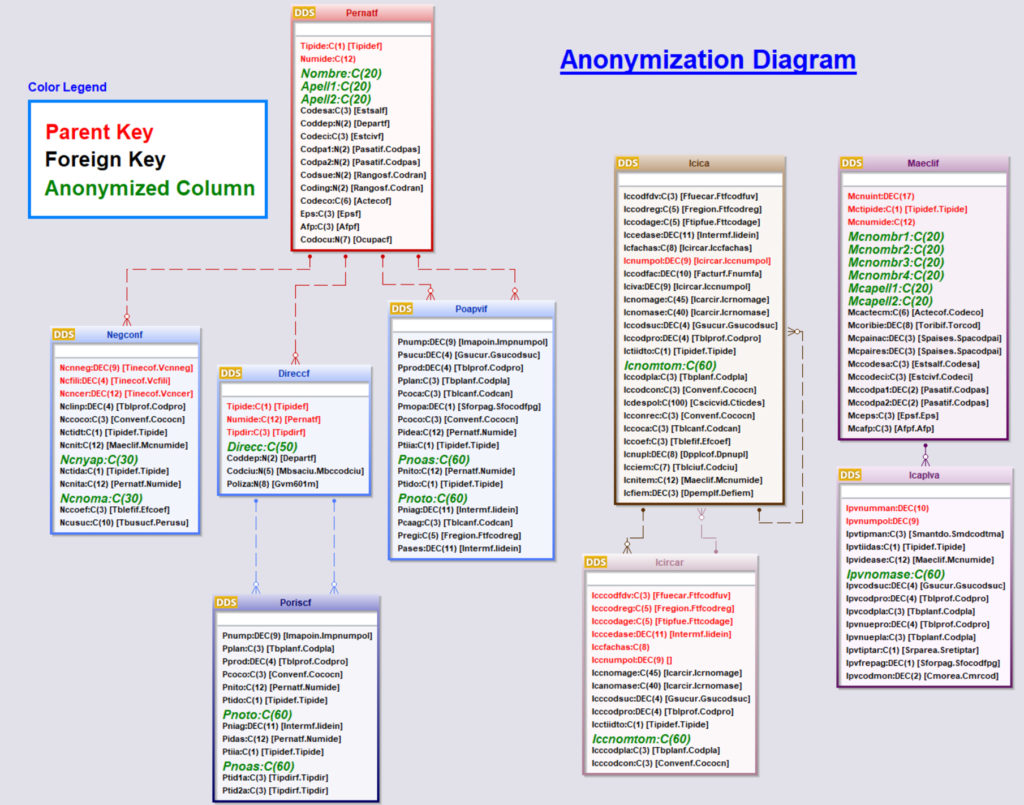
Once anonymized, developers have a high level of freedom for their tests, and Development teams can work free of constraint with high-quality data without endangering compliance with legal regulations or internal business rules.
Provides the anonymization manager with a user-friendly and effective tool to anonymize sensitive business or personal data in your Dev/Test databases
Your security and legal compliance are enforced.
- This module can be used as a complete stand-alone solution (independent of other Xcase for i solutions) to comply with your regulation obligations.
- Anonymize-DB supports multiple concurrent RDBMS (DB2, SQL Server, My SQL…)




What is the Anonymize-DB methodology?
