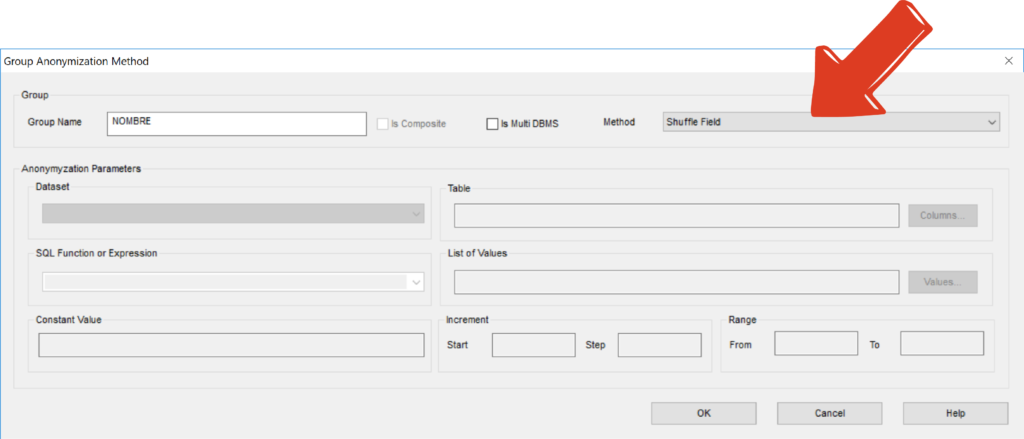
The same data often appears in multiple locations across the database. It is crucial to identify the group of columns belonging to the same “domain” in order to anonymize them consistently
 Redundant data (DB is not Normal and the same data appears in multiple places)
Redundant data (DB is not Normal and the same data appears in multiple places)- Repeated data (PK, FK chains allowing to link tables)
- Calculated data (e.g.: The concatenation of Name and Surname of the customer is stored. It needs to be re-calculated after the Name and the Surname have been anonymized to preserve coherence)
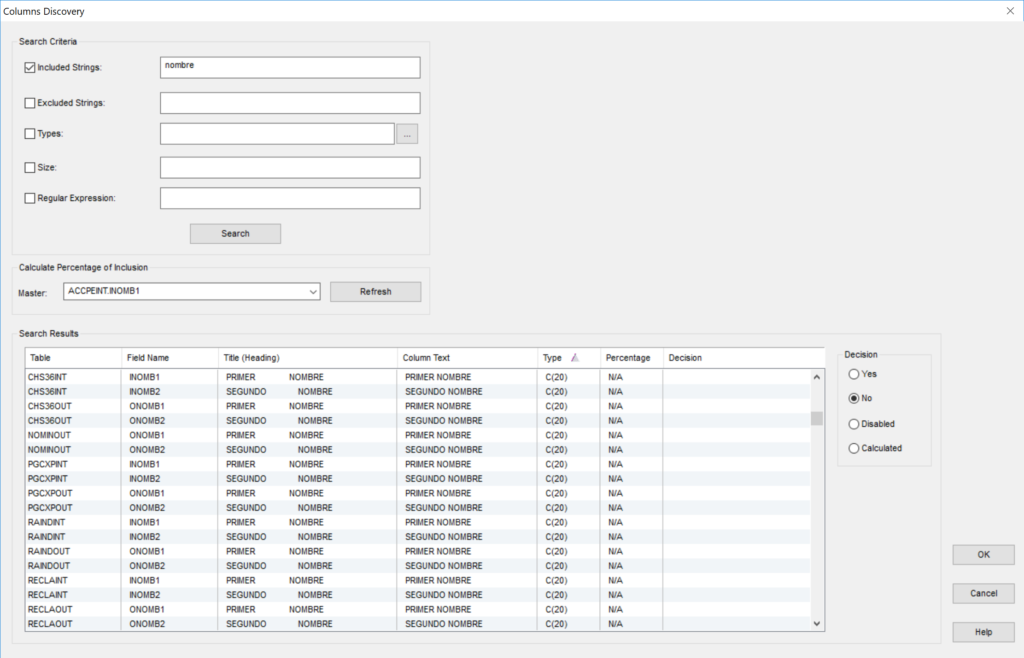
- Anonymize DB allows you to identify column groups by searching the metadata for columns belonging to the same group according to physical attributes, semantic data (column vocabulary found in the name, text, or heading of the column) and even physical data to verify that the columns in the group belong to the same domain.

")
")
")


")

")