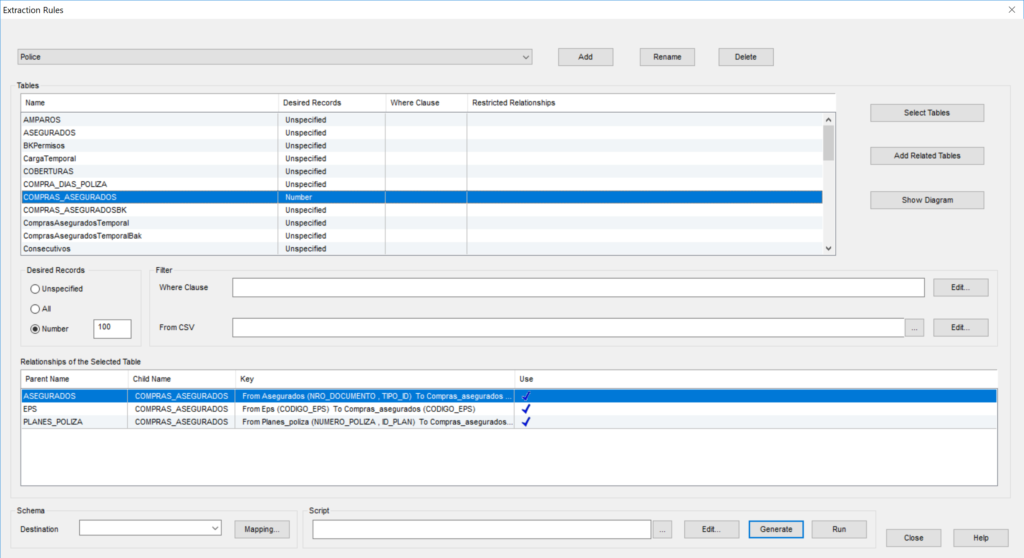
Step One: Database relationships discovery
With its unique, data-centric approach, Xcase for i exploits all the information available in the meta and physical data to automate the discovery of the relationships hidden in the database.
The following outlines the algorithm used for the automatic relationship discovery:
 Determine which tables are relational (exclude work files)
Determine which tables are relational (exclude work files)- Qualify candidate Parent Keys and Children
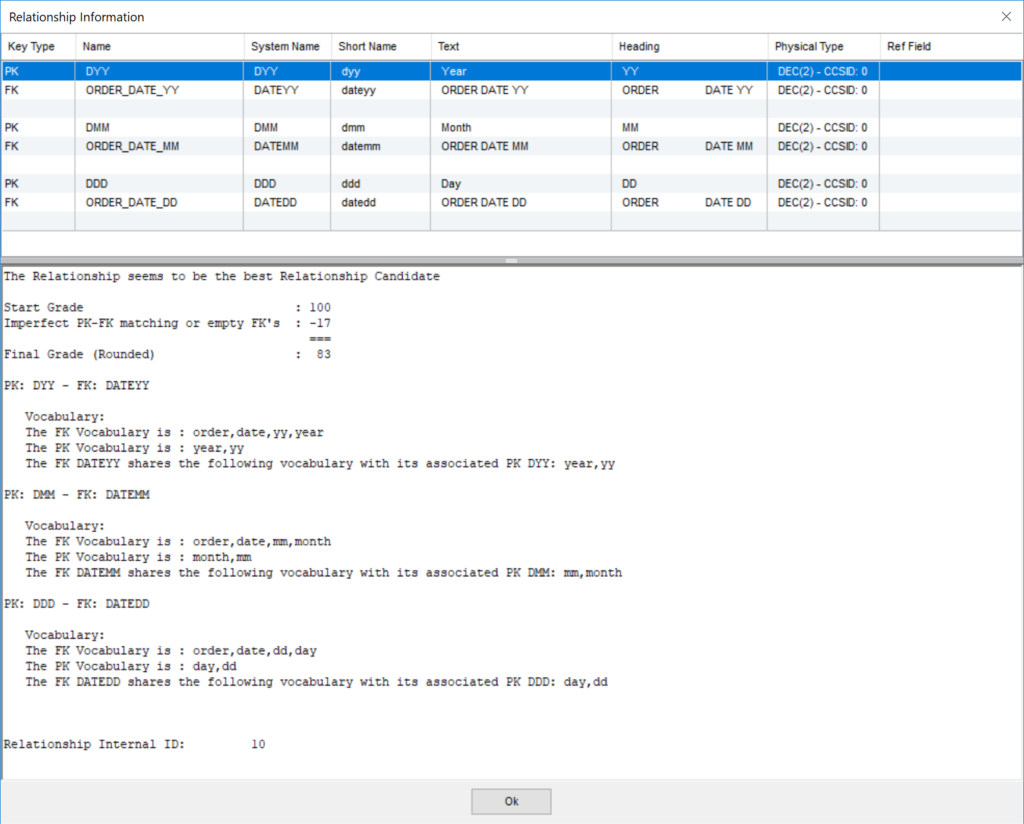
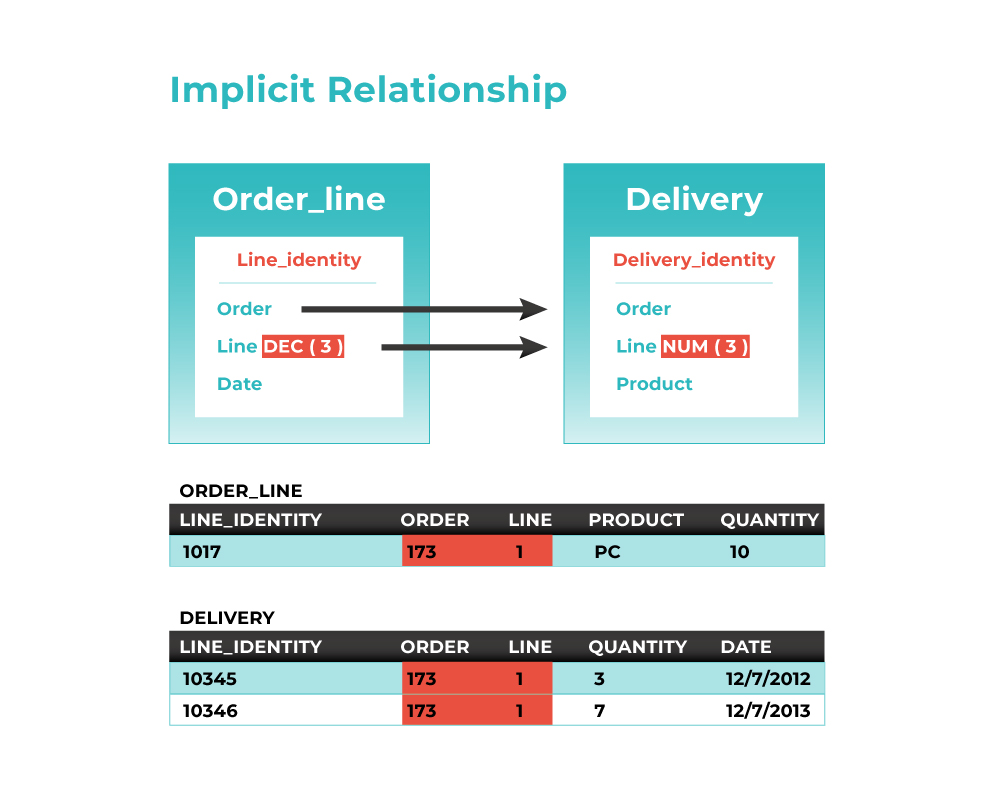
- Match PK and FK elements using metadata and common vocabulary (semantics)
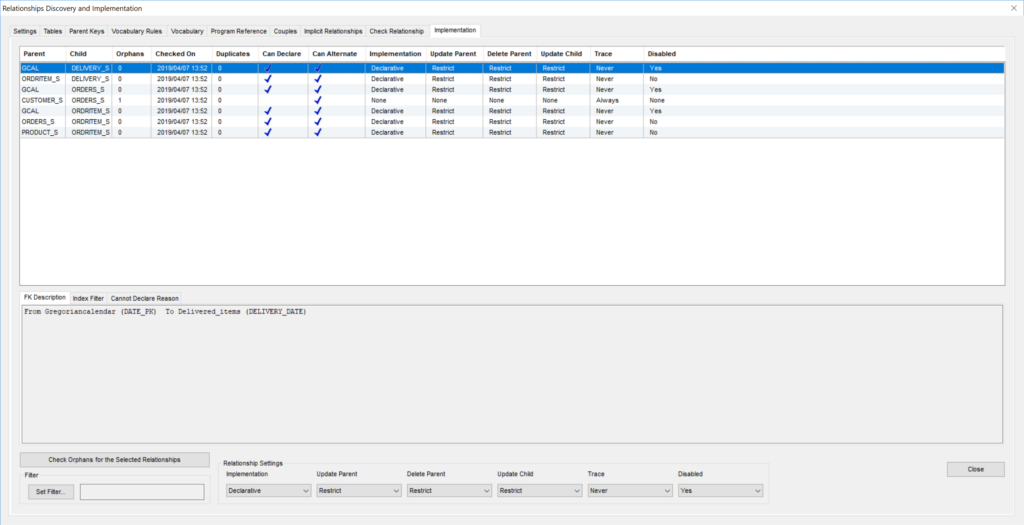
- Check candidate relationships using physical data
- Provide a grade and detailed diagnostic to help you validate the results
Time, effort and risk of errors are reduced. Your team only has to validate the small set of relationships selected among the hundreds of thousands of possibilities.