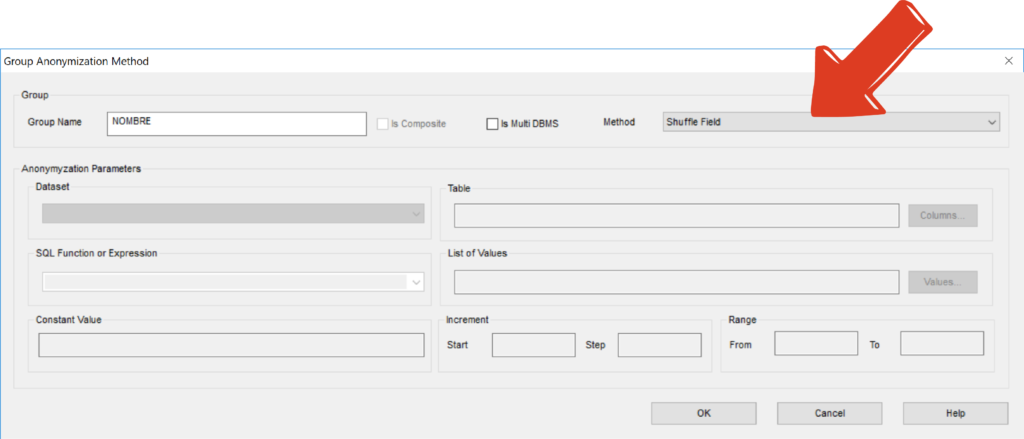
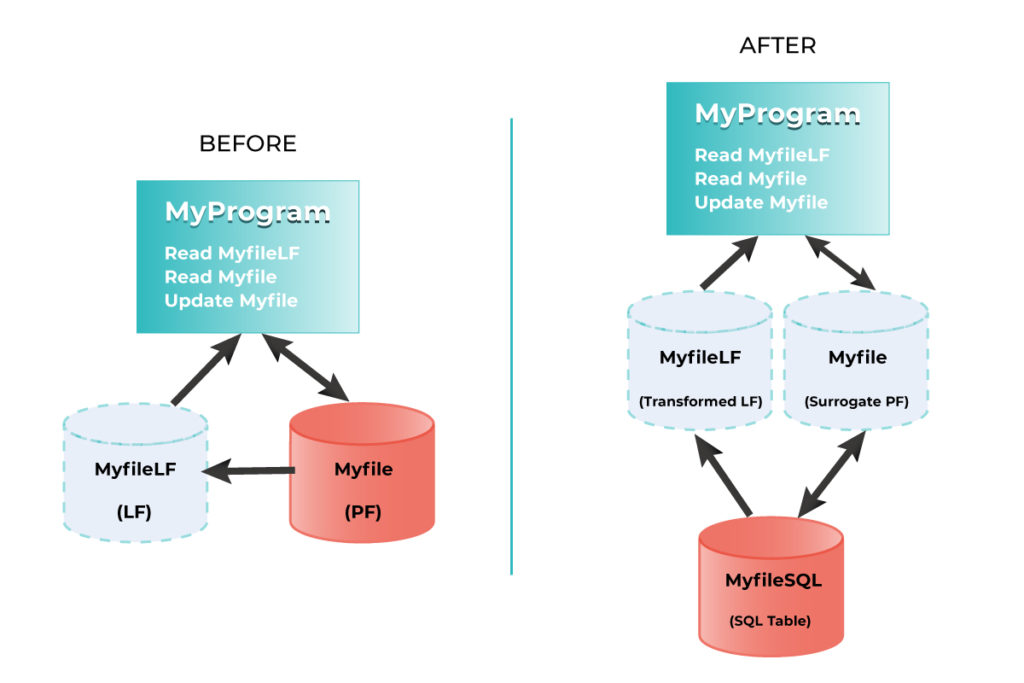
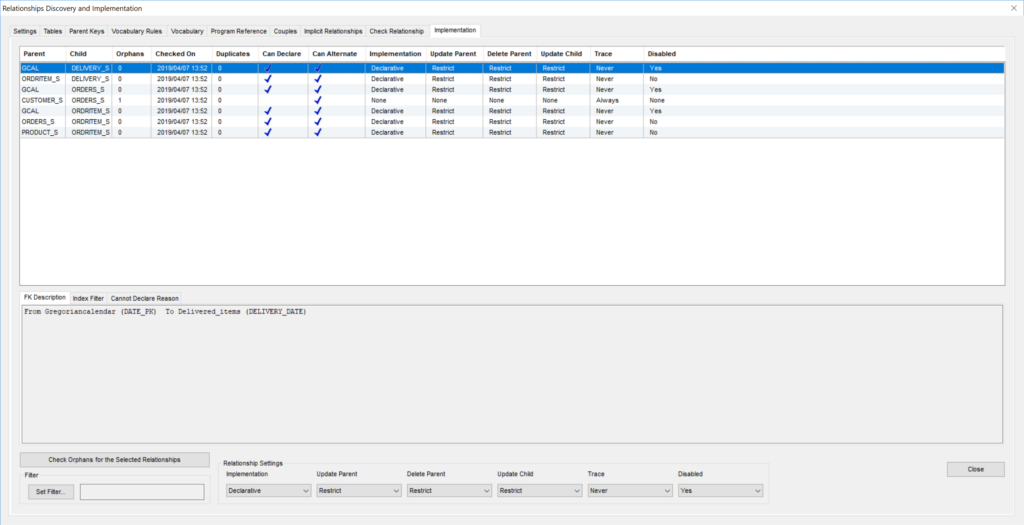
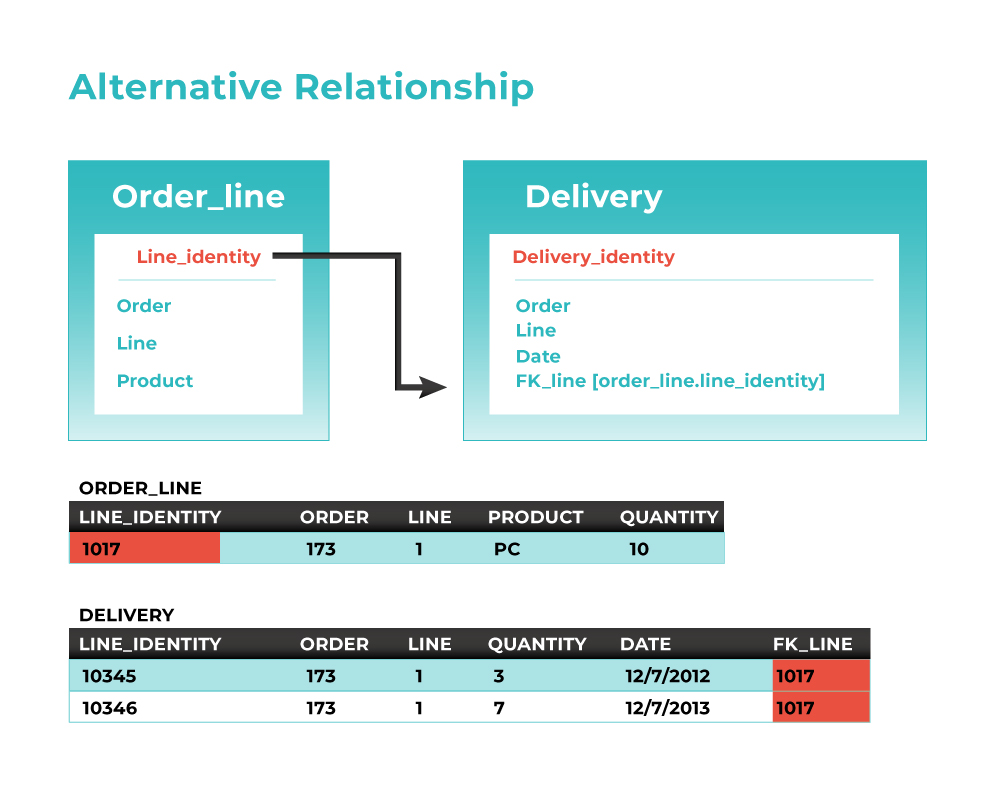
In those cases, an Alternative Relationship can be implemented between the Parent Identity and a newly created FK mapping to it in the Child. When properly set this yield to a functionally equivalent relationship producing for the same Parent the same children and for the same Child the same Parent as the original discovered relationship.
A set of automatically generated triggers updates the new FK when the old FK is modified and vice-versa. This way old applications (using the old FK) and new applications (using the new FK) can co-exist as each gets the data it needs.
Note that the triggers produce minimal overhead and are activated only when modifying data. When reading data (which happens on average 20 times more frequently) you immediately benefit from an optimized Identity based relationship.
Note also than when the old applications have been upgraded to use the new relationship, you can get read of the old FK and the triggers.
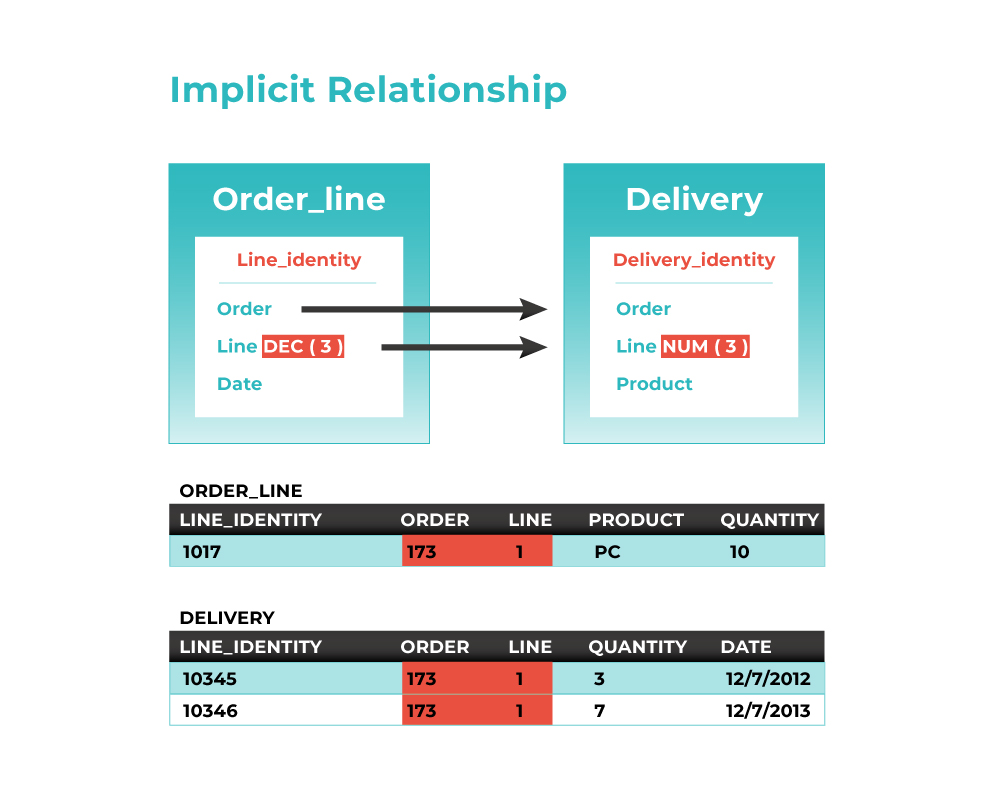
The following diagram illustrated the “Alternative Relationship” concept.

")
")
")


")

")